Abstract
Long-context autoregressive modeling has significantly advanced language generation, but video generation still struggles to fully utilize extended temporal contexts. To investigate long-context video modeling, we introduce Frame AutoRegressive (FAR), a strong baseline for video autoregressive modeling. Just as language models learn causal dependencies between tokens (i.e., Token AR), FAR models temporal causal dependencies between continuous frames, achieving better convergence than Token AR and video diffusion transformers. Building on FAR, we observe that long-context video modeling faces challenges due to visual redundancy. Training on long videos is computationally expensive, as vision tokens grow much faster than language tokens. To tackle this issue, we propose balancing locality and long-range dependency through long short-term context modeling. A high-resolution short-term context window ensures fine-grained temporal consistency, while an unlimited long-term context window encodes long-range information using fewer tokens. With this approach, we can train on long video sequences with a manageable token context length, thereby significantly reducing training time and memory usage. Furthermore, we propose a multi-level KV cache designed to support the long short-term context modeling, which accelerating inference on long video sequences. We demonstrate that FAR achieves state-of-the-art performance in both short- and long-video generation, providing a simple yet effective baseline for video autoregressive modeling.
What is the potential of FAR compared to video diffusion transformers?
- FAR requires same training cost to video diffusion transformers.
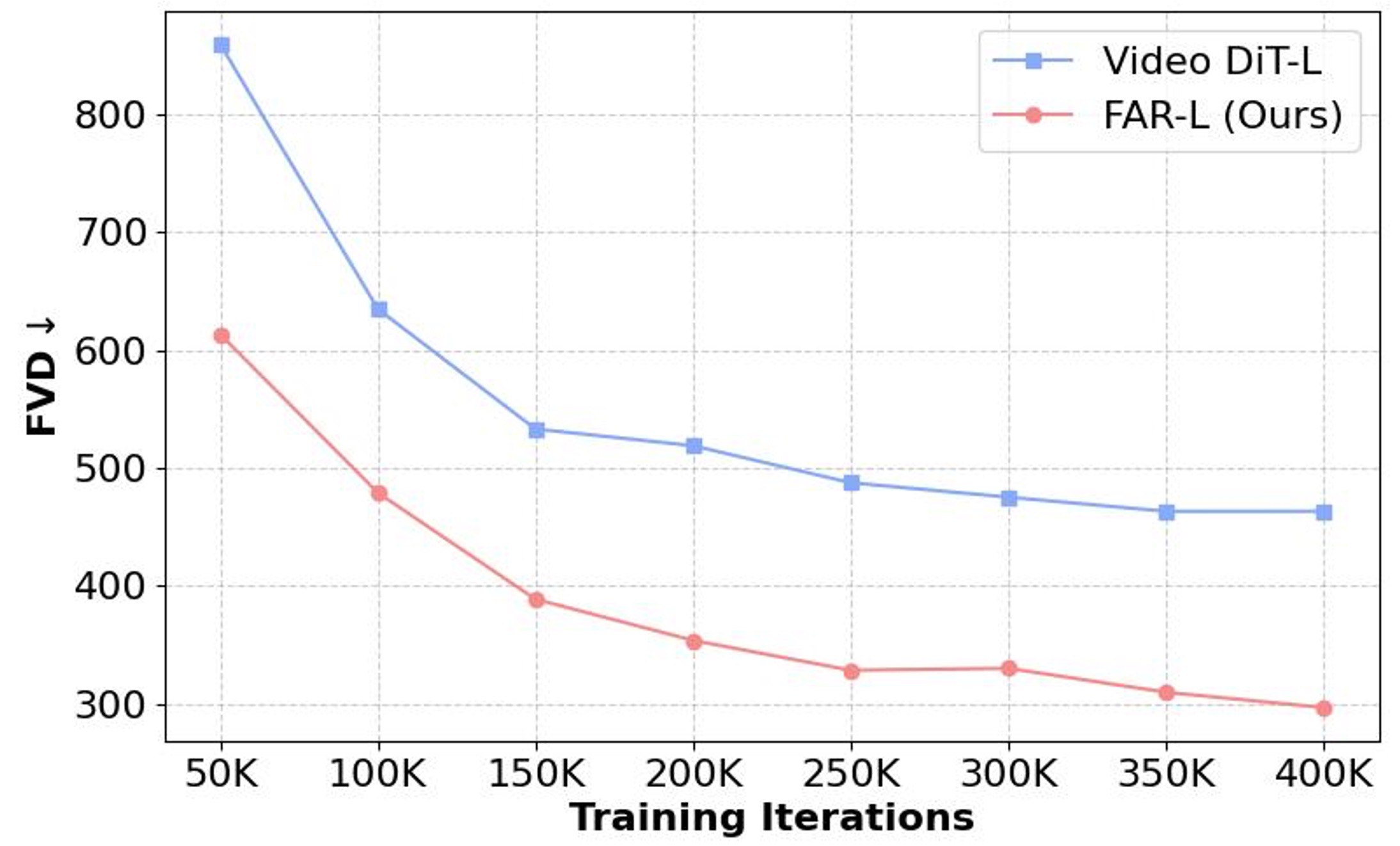
- FAR achieves better convergence than video diffusion transformers with the same latent space.
2. Native Support for Vision Context:
- Video diffusion transformers: requires additional image-to-video fine-tuning to expolit image conditions.
- FAR: provides native support for clean vision context at various lengths, achieving state-of-the-art performance in video generation (context frame = 0) and video prediction (context frame ≥ 1).
3. Efficient Training on Long Video Sequence:
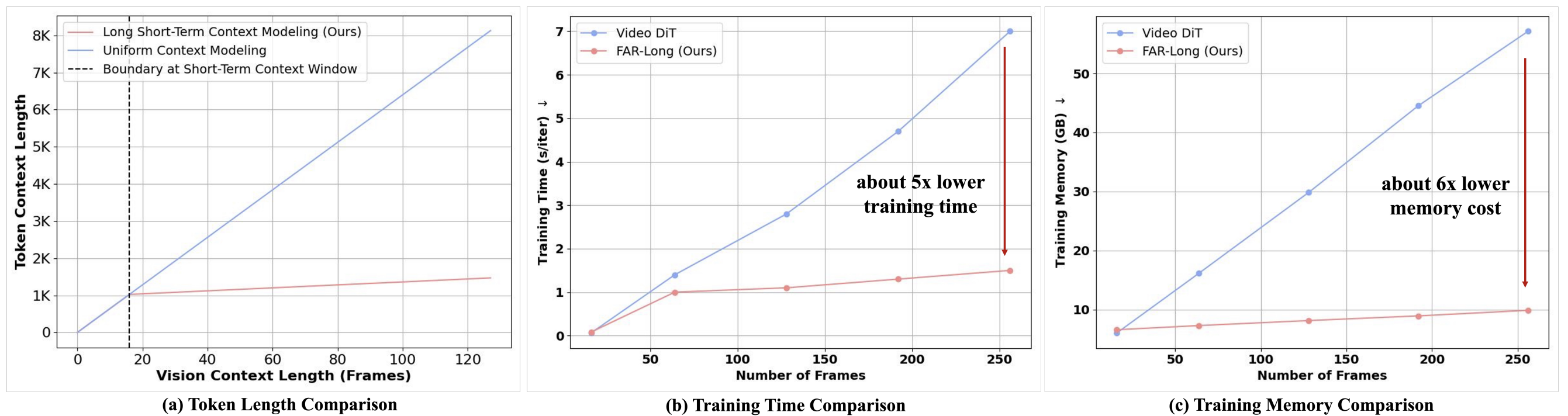
- Video diffusion transformers: cannot efficiently train on long videos because the vision token scales rapidly with the number of frames.
- FAR: exploits long short-term context modeling, reduce redundant token lengths during training or fine-tuning on long videos.
4. Fast Autoregressive Inference on Long Video Sequence:
- Video diffusion transformers: cannot directly autoregressive inference for long-video without image-to-video finetuning.
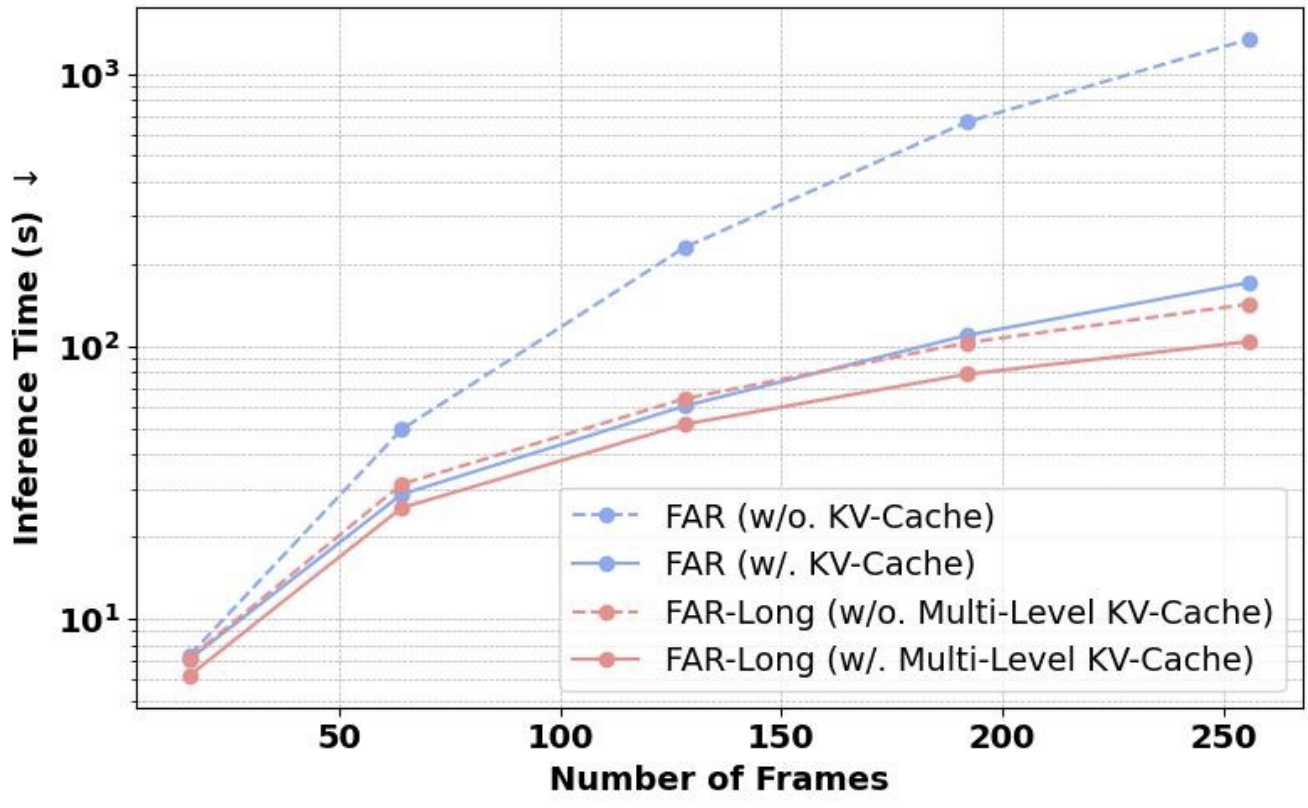
- FAR: exploits multi-level kv cache to speedup autoregressive inference on long videos.
Pipeline
Key Techniques:
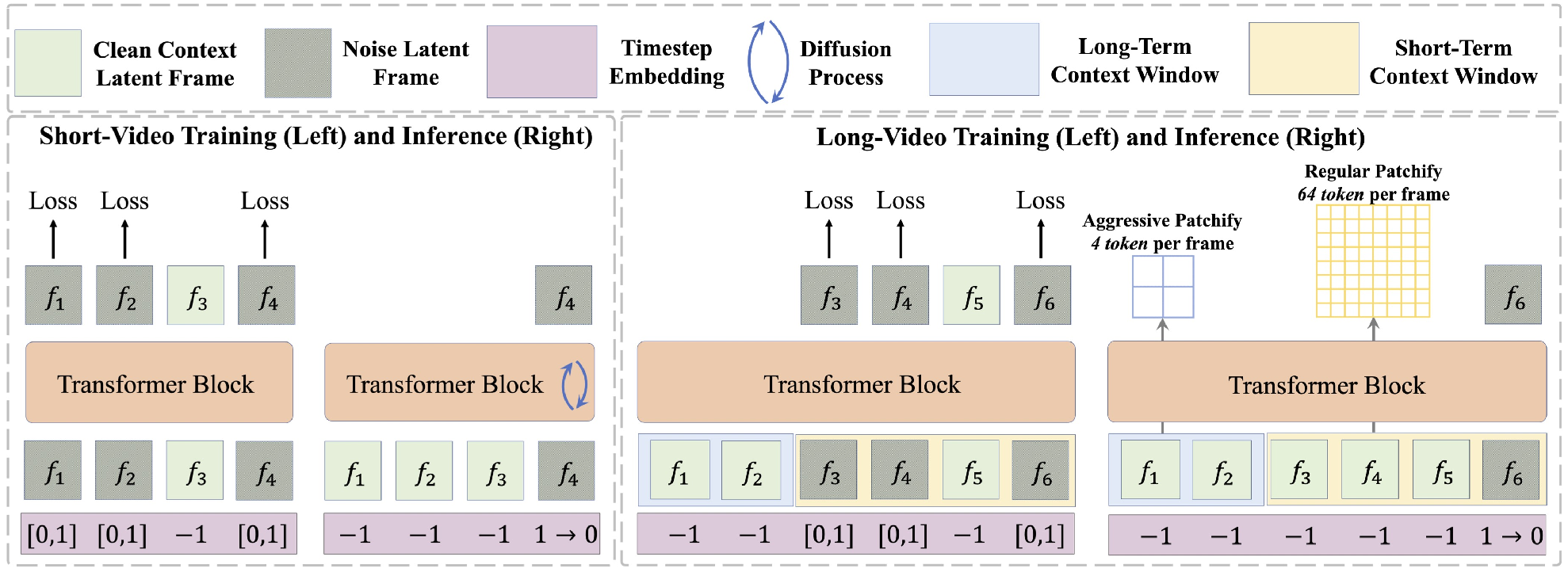
- Stochastic Clean Context: In training, we stochastically replace a portion of noisy context with clean context frames and use timesteps beyond the diffusion scheduler (e.g., -1) to indicate them. This strategy bridges the training and inference gap of observed contexts without incurring additional training costs.
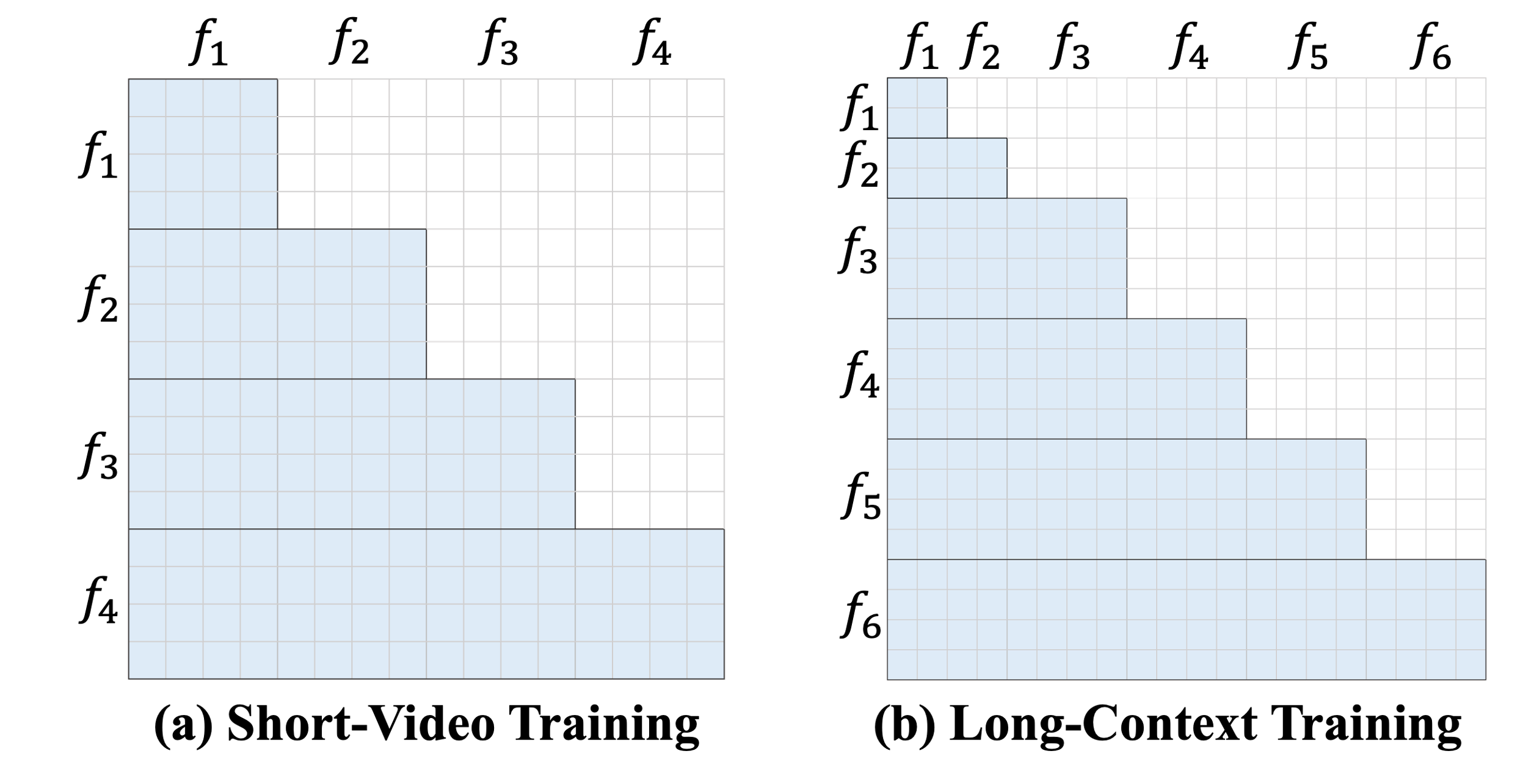
- Long Short-Term Context Modeling: To reduce the training cost on long-video sequences, we maintain a high-resolution short-term context window to model fine-grained temporal consistency, and an unlimited long-term context window to reduce redundant tokens with aggressive patchification.
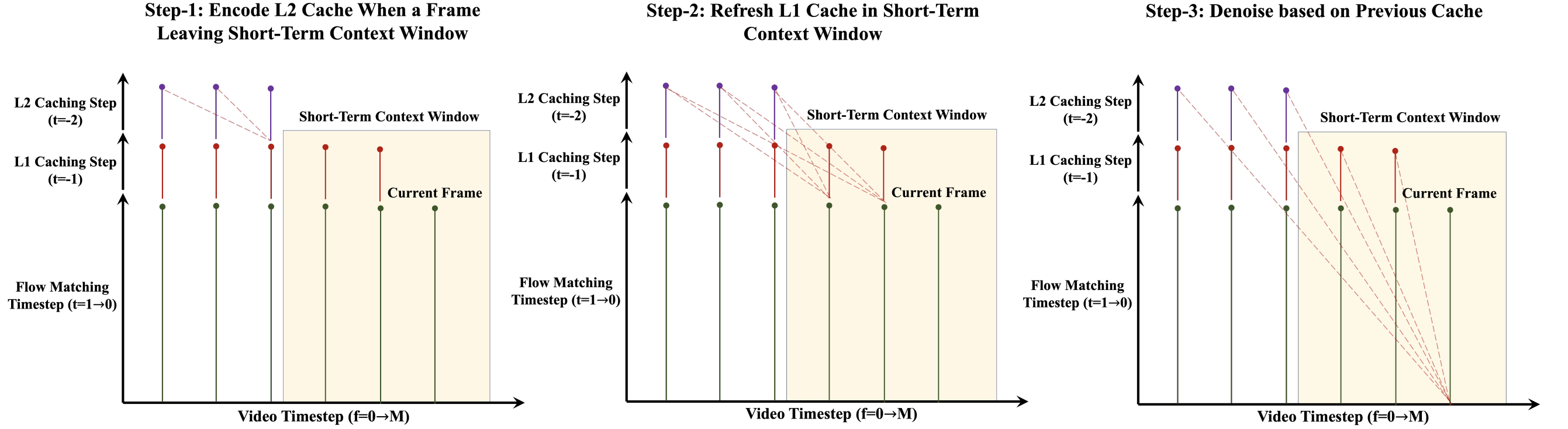
- Multi-Level KV Cache: To speedup autoregressive inference on long-video sequences, we schedule long-term and short-term context with multi-level KV cache.
Main Results
(red boxes: observed context frames, left: prediction, right: ground-truth)

2. FAR achieves state-of-the-art performance on unconditional/conditional video generation, short-video prediction and long-video preidction.
BibTeX
@article{gu2025long,
title={Long-Context Autoregressive Video Modeling with Next-Frame Prediction},
author={Gu, Yuchao and Mao, weijia and Shou, Mike Zheng},
journal={arXiv preprint arXiv:2503.19325},
year={2025}
}